
32
Vizualizări

Noul algoritm „Yandex“ convertește cererea de căutare, și mai multe site-uri de pe unitățile semantice sau vectorii așa-numitele semantice. Odată ce un utilizator introduce o interogare, motorul de căutare compară vectorii cu titlul și conținutul site-urilor cu potențial adecvate. Algoritmul precedent „Palekh“ ar putea compara doar vectorii semantice ale cererii și antete, și „Korolev“ scanează paginile web în întregime.
„Yandex“, explică algoritmul „Korolev“ ca un exemplu de „Război și Pace“. Versiunea anterioară poate căuta numai pentru a găsi o carte după titlu sau cuvinte cheie asociate cu conținutul: numele personajelor, titlurile capitolelor, și așa mai departe. Un nou algoritm citește ca un roman și pe deplin înțelege sensul narativ.
Potrivit dezvoltatorilor, principalul avantaj de a înțelege sensul interogările că limba de căutare devine mai umană. Utilizatorul nu poate căuta un film după nume, ci doar descrie pe scurt complot. De exemplu: „un film despre spațiul în care eroul a vorbit cu fiica ei prin ceas.“ De algoritm își dă seama că există un film „Interstellar“, în cazul în care eroul este Matthew McConaughey a fost în spațiu și a folosit ceasul pentru a comunica cu fiica ei. Și acest film va fi afișat în rezultatele căutării.
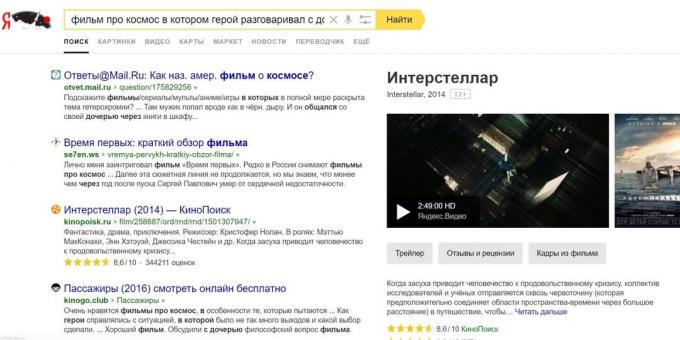
Pentru a căuta înțelegerea ca sensul interogarea se referă la conținutul unei pagini web, aveți nevoie pentru a utiliza o rețea neuronală pe scară largă. Pentru formarea ei vor avea nevoie de miliarde de exemple, de ce utilizatorii „Yandex“ pentru a utiliza algoritmii lor de formare.
În cazul în care o persoană este mutat din rezultatele căutării la site-ul și a rămas pe ea, cel mai probabil, algoritmul a lucrat în mod corespunzător. Rețeaua neuronală este antrenat pe un exemplu negativ: dacă site-ul este închis imediat în jos sau a ratat doar, sistemul va aminti. Așa că, în viitor căutare ar trebui să funcționeze mai bine și mai bine.

